

반응형
히트맵과 클러스터맵은
모두 데이터의 관계를
시각화하는 데 사용되는
시각화 방법입니다.
히트맵은 데이터의 값을
2차원 격자에 매핑하여
데이터의 분포를 보여줍니다.
sns.heatmap(df.corr(), cmap='viridis')

클러스터맵은 히트맵의 데이터를
클러스터링하여
데이터의 군집을 보여줍니다.
sns.clustermap(df.corr(), annot = True, cmap = 'RdYlBu_r', vmin = -1, vmax = 1, )

히트맵과 클러스터맵의 차이점은
히트맵은 데이터의 분포만을 보여줍니다.
반면, 클러스터맵은 데이터의 분포와
군집을 모두 보여줍니다.
따라서 클러스터맵은 히트맵보다
데이터의 관계를 이해하는 데
더 도움이 될 수 있습니다.
예를 들어, 고객의 구매 내역을
히트맵으로 시각화하면
고객의 구매 패턴을 알 수 있습니다.
그러나 클러스터맵으로 시각화하면
고객을 군집으로 나눌 수 있습니다.
각 군집의 특성을 분석하면
고객의 구매 패턴을
더 잘 이해할 수 있습니다.
다음은 중복을 제거한
히트맵 시각화 파이썬 코드
# 중복 제거 히트맵 시각화
# 매트릭스의 우측 상단을 모두 True인 1로, 하단을 False인 0으로 변환.
np.triu(np.ones_like(df.corr()))
# True/False mask 배열로 변환.
mask = np.triu(np.ones_like(df.corr(), dtype=np.bool))
# 히트맵 그래프 생성
fig, ax = plt.subplots(figsize=(15, 10))
sns.heatmap(df.corr(),
mask=mask,
vmin=-1,
vmax = 1,
annot=True,
cmap="RdYlBu_r",
cbar = True)
ax.set_title('Wine Quality Correlation', pad = 15)
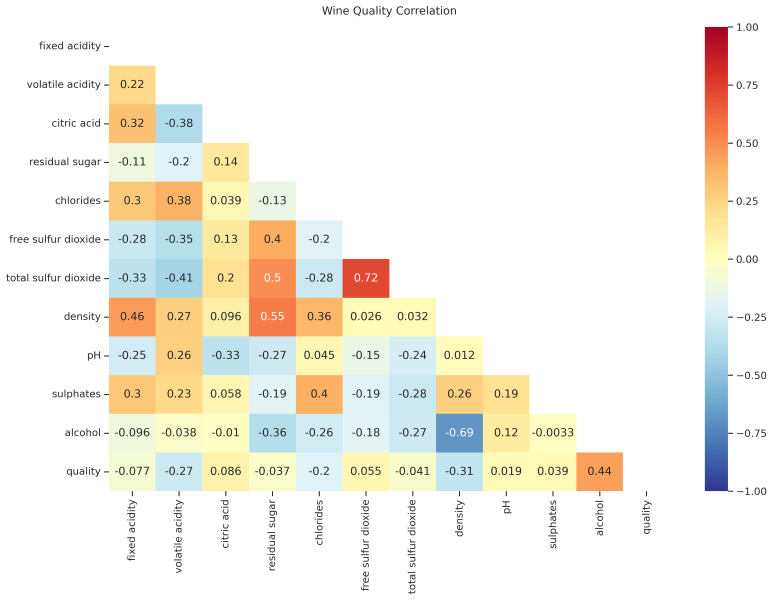
중복 영역이 제거된 히트맵 시각화
반응형
'Data Science' 카테고리의 다른 글
| 머신러닝(기계학습)에서 목적함수의 정의 (0) | 2023.10.13 |
|---|---|
| [학교 선생님을 위한 파이썬교재] 나는 파이썬으로 머신러닝한다 (0) | 2023.08.09 |
| [데이터과학] 왜도(skewness)와 첨도(kurtosis) (0) | 2023.06.09 |
| [용인 명지대 맛집] 호접몽 맛있는데 음식에서 ㅇㅇ이 나왔어요 (0) | 2023.05.25 |
| [인공지능] 지도학습 분류 vs 비지도학습 군집화 비교 (0) | 2023.05.23 |