

반응형
CH 02-01. 판다스 기초_피벗 테이블.ipynb
0.06MB
CH 02-01. 판다스 기초_피벗 테이블.py
0.01MB
#!/usr/bin/env python
# coding: utf-8
# ## 02. 테이블 = DataFrame
# ### 이번 실습에서는 다음 내용들을 배웁니다.
#
#
# - pandas의 기본 구조인 DataFrame을 이해하고, pandas에 대한 다양한 데이터 처리 기능에 대해 배웁니다.
#
#
# - 파이썬에서 엑셀 데이터를 사용하는 방법에 대해 배웁니다.
# In[2]:
# pandas 라이브러리를 불러옵니다. pd를 약칭으로 사용합니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# - DataFrame은 2차원 테이블이고, 테이블의 한 줄(행/열)을 Series라고 합니다.
#
#
# - Series의 모임이 곧, DataFrame이 됩니다.
# In[3]:
# s는 1, 3, 5, 6, 8을 원소로 가지는 pandas.Series
pd.Series([1,3,5,6,8])
# In[4]:
# 12x4 행렬에 1부터 48까지의 숫자를 원소를 가지고, index는 0부터 시작하고, coulmns은 순서대로 X1, X2, X3, X4로 하는 DataFrame 생성
df = pd.DataFrame(data= np.arange(1,49).reshape(12,4),
columns = ["x1","x2","x3","x4"])
df
# In[5]:
# dataframe index
df.index
# In[6]:
# dataframe columns
df.columns
# In[7]:
# dataframe values
df.values
# In[8]:
# 특정 column을 가져오기
df["x1"]
# In[9]:
# X1 column에 2 더하기
df["x1"] +2
# In[10]:
# dataframe의 맨 위 다섯줄을 보여주는 head()
df.head()
# In[11]:
# 10줄
df.head(10)
# In[12]:
# dataframe에 대한 전체적인 요약정보를 보여줍니다. index, columns, null/not-null/dtype/memory usage가 표시됩니다.
df.info()
# In[13]:
# dataframe에 대한 전체적인 통계정보를 보여줍니다.
df.describe()
# In[14]:
# X2 column를 기준으로 내림차순 정렬
df.sort_values(by="x2", ascending = False)
# ## 03. 원하는 데이터를 찾아오자
# ### Fancy Indexing ! (***)
#
# - 데이터를 filtering <=> Search !
#
# - 전체 데이터에서 원하는 일부의 데이터를 찾아오는 방법 !
# In[15]:
# pandas dataframe은 column 이름을 이용하여 기본적인 Indexing이 가능합니다.
# X1 column을 indexing
df["x1"]
# In[16]:
# dataframe에서 slicing을 이용하면 row 단위로 잘려나옵니다.
# 앞에서 3줄을 slicing 합니다.
df[:3]
# In[17]:
# df에서 index value를 기준으로 indexing도 가능합니다. (여전히 row 단위)
# 두번째 row
df.loc[0]
# In[20]:
# df.loc는 특정값을 기준으로 indexing합니다. (key - value)
df.loc[0][2]
df.loc[0]["x3"]
# In[23]:
# df.loc에 2차원 indexing도 가능합니다.
# df.loc["row에 대한 조건(index)","col에 대한 조건(col name)"]
df.loc[4,"x2"]
df.loc[[0,3],["x1","x3"]]
df.loc[0:4,"x1":"x3"] # loc로 슬라이싱 하면 모든 범위가 포함. 주의!!
# In[27]:
## boolean mask == filter
mask = df["x1"] > 10 # row에 대한 조건
df.loc[mask]
# Q. df에서 X2 column이 20 이상인 모든 데이터(row)를 출력하세요.
mask2 = df["x2"] > 20
df.loc[mask2]
# Q2. df에서 X2 column이 20 이상인 X4를 출력하세요.(예. 나이가 30 이상인 사람들의 연봉)
df.loc[df["x2"] >= 20, "x4"]
# In[28]:
# Q3. X3 column에서 10 이상 30 이하인 데이터를 뽑아주세요.
mask3 = (10 <= df["x3"]) & (df["x3"] <= 30)
df.loc[mask3]
# Q4. X2 column에서 10보다 작거나 30 이상인 데이터를 뽑아주세요.
# In[29]:
# iloc로 2차원 indexing을 하게되면, row 기준으로 index 3,4를 가져오고 column 기준으로 0, 1을 가져옵니다.
# Q. 3번째 row부터 8번째 row까지, 첫번째 column부터 3개
df.iloc[2:7, 0:3]
# ## 04. 엑셀의 피벗 테이블? 판다스에도 있다!
#
# - pivot table이란 기존 테이블 구조를 특정 column을 기준으로 재구조화한 테이블을 말합니다.
#
# - 특정 column을 기준으로 pivot하기 때문에, 어떤 column에 어떤 연산을 하느냐에 따라서 만들어지는 결과가 바뀝니다.
#
# - 주로 어떤 column을 기준으로 데이터를 해석하고 싶을 때 사용합니다.
# Data Source : https://www.kaggle.com/c/titanic/data
# In[30]:
# 타이타닉 데이터 불러오기
#./폴더명/파일명
titanic = pd.read_csv("titanic.csv")
titanic
# In[31]:
# 데이터 크기, 데이터 Column 정보, Null count(결측치 개수), column별 데이터 타입
titanic.info()
# 통계량
titanic.describe()
# In[32]:
# 나이가 30이상인 사람들의 이름
titanic.loc[titanic["Age"] >= 30, "Name"]
# In[33]:
# 성별을 기준으로 생존률 파악 --> Mean vs Sum
pd.pivot_table(data = titanic, index="Sex", values="Survived") # 평균으로 합쳐진다.
# In[35]:
# 성별을 기준으로 생존률 파악 --> Mean vs Sum
pd.pivot_table(data = titanic,
index="Sex",
values="Survived",
aggfunc=["mean", "sum","count"])
# In[38]:
# 사회 계급을 기준으로 생존률 파악
pd.pivot_table(data = titanic,
index="Pclass",
values="Survived",
aggfunc=["count","sum","mean"])
# In[39]:
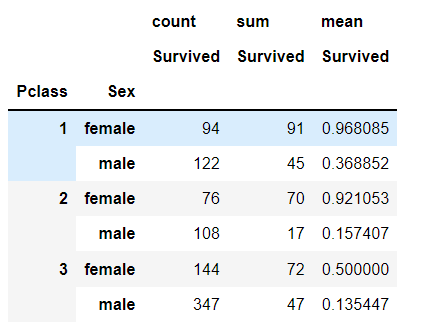
# 사회 계급을 기준으로 생존률 파악
pd.pivot_table(data = titanic,
index=["Pclass","Sex"],
values="Survived",
aggfunc=["count","sum","mean"])반응형
'Data Science' 카테고리의 다른 글
| [판다스] 여러 엑셀 파일 합치기 (0) | 2023.01.31 |
|---|---|
| seaborn 그래프_경향성_크기_분포 파악 (0) | 2023.01.31 |
| 살아움직이는 그래프 plotly (0) | 2023.01.31 |
| 여러 데이터 쉽게 불러오기 (0) | 2023.01.31 |
| [파이썬] 웹크롤링 주식 데이터 가져오기 (0) | 2023.01.30 |