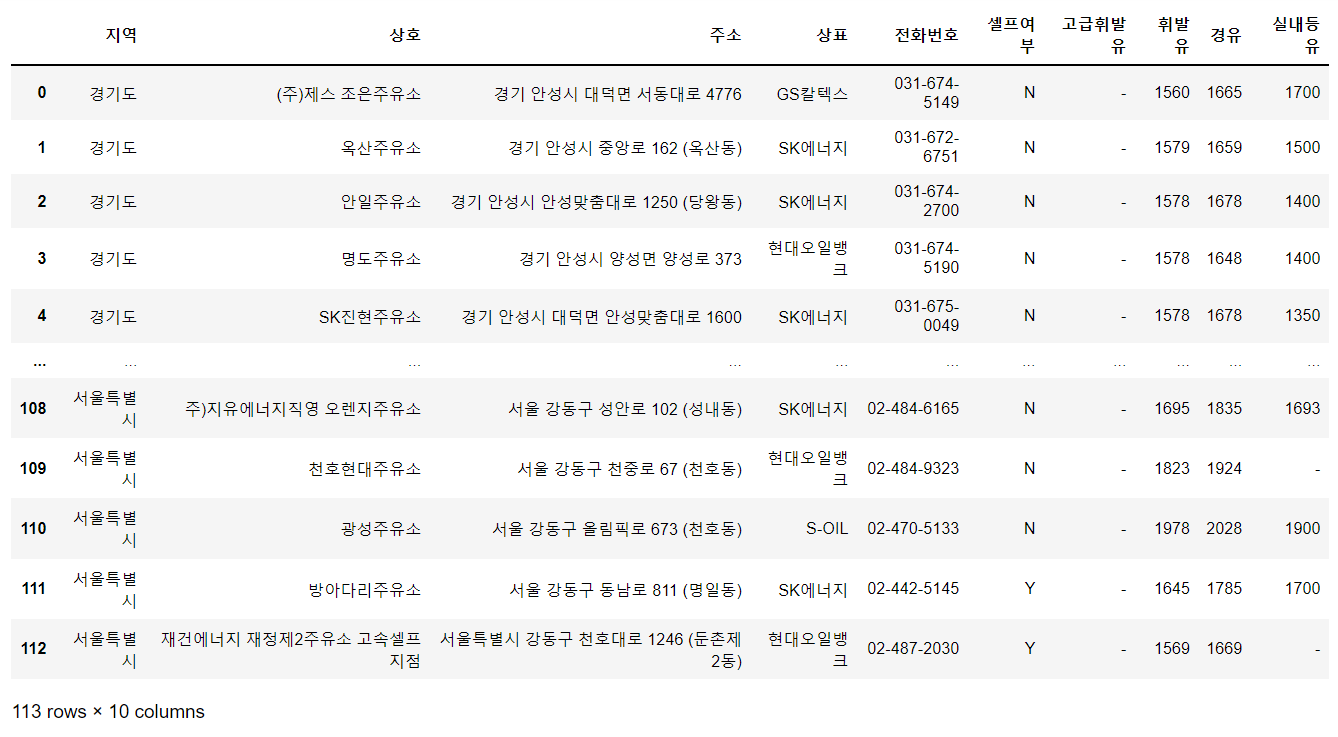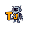
# -*- coding: utf-8 -*- """혼공머신러닝_ch1.ipynb Automatically generated by Colaboratory. Original file is located at https://colab.research.google.com/drive/1yyi3uGfURyYiKYLsQsXAJUsR9X-n9rML """ # 데이터의 특성 bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0, 31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0, 35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 3..