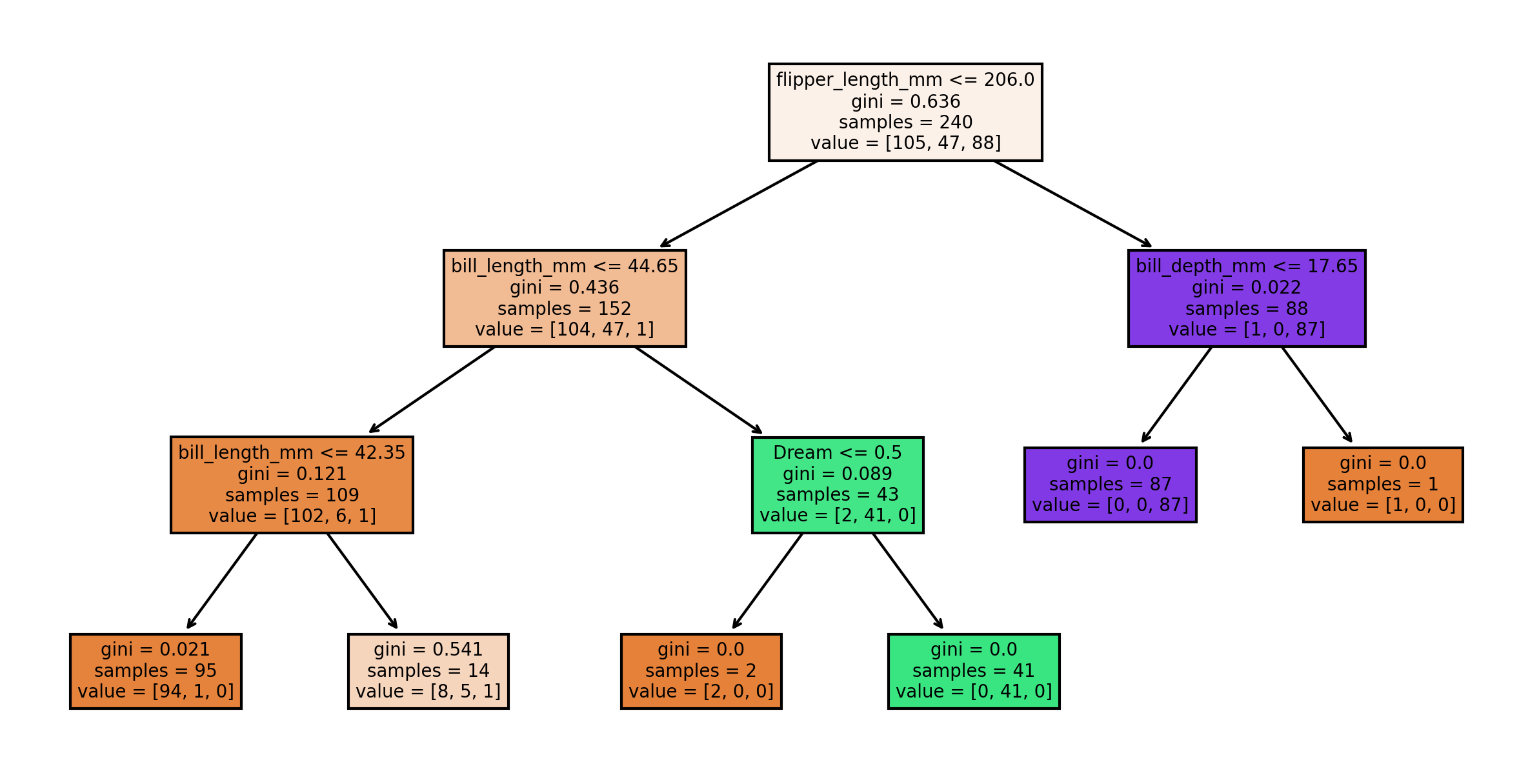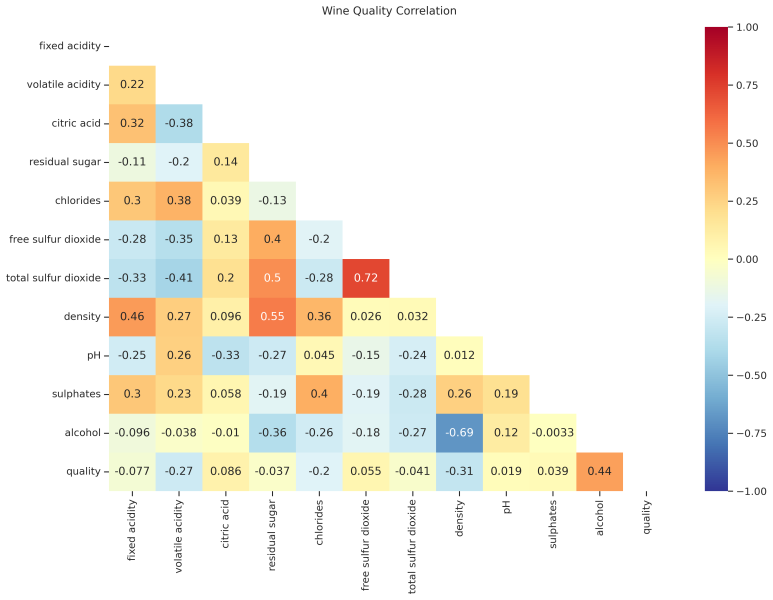
import os import pandas as pd import numpy as np import sklearn from sklearn.tree import DecisionTreeClassifier from sklearn.tree import export_text, export_graphviz from sklearn.model_selection import train_test_split from sklearn.metrics import confusion_matrix import matplotlib.pyplot as plt import seaborn as sns penguins = sns.load_dataset('penguins') print (penguins.shape) penguins.head() p..